Overview
Mulkiya-OCR is an experiment app, I’ve used Tesseract Open Source OCR engine to read text from images(for example mulkiya image) so that data input process can be automated and accurate as much as possible. The code is open source at github.
For those who are not familiar with word “Mulkiya”. It’s an arabic word which means vehicle registration card or vehicle ownership certificate.
Getting Started
- Install tesseract-ocr open source OCR engine
git clone [email protected]:minhajkk/mulkiya-ocr.gitclone repo from githubnpm installInstall the dependencies in the localnode_modulesfolder.bower instalkInstall client side bower dependencies.npm startto run the application.
Demo
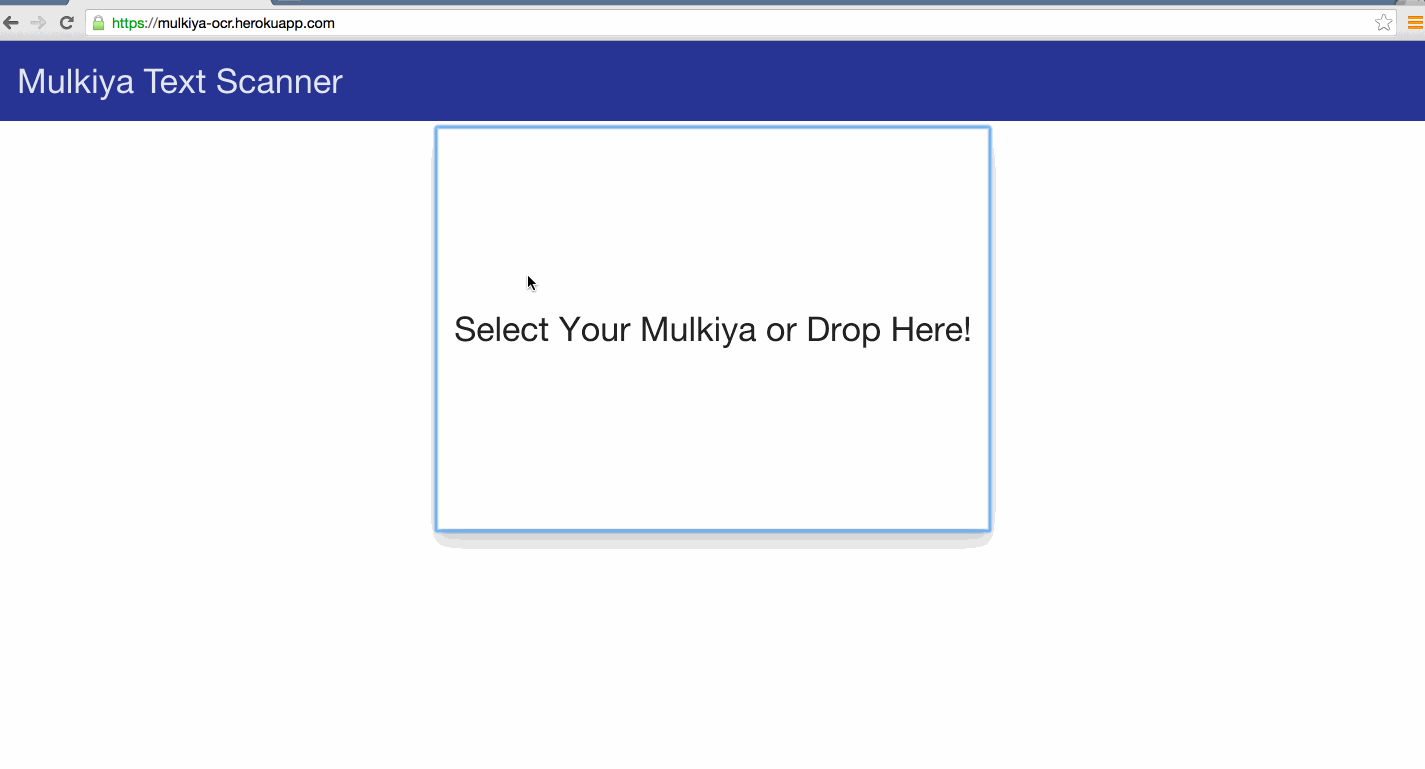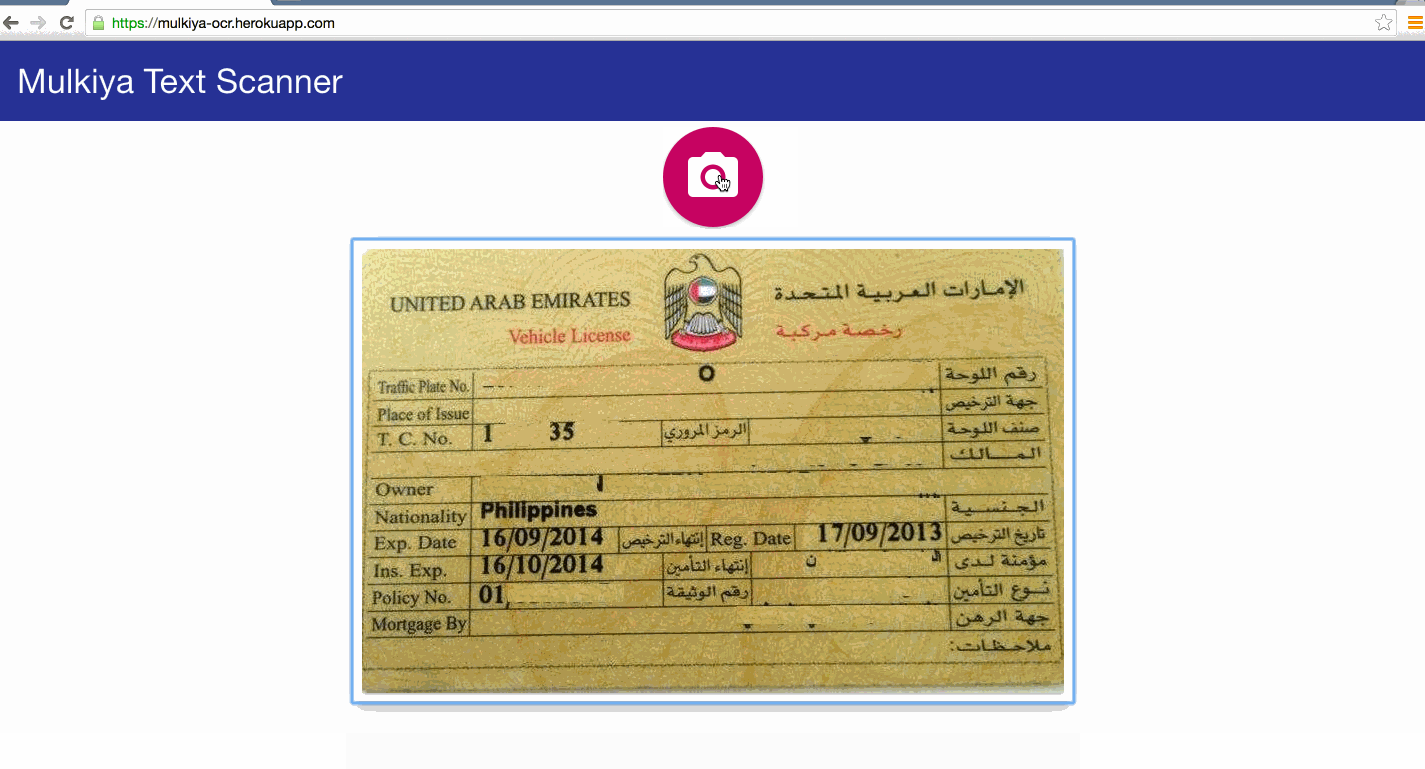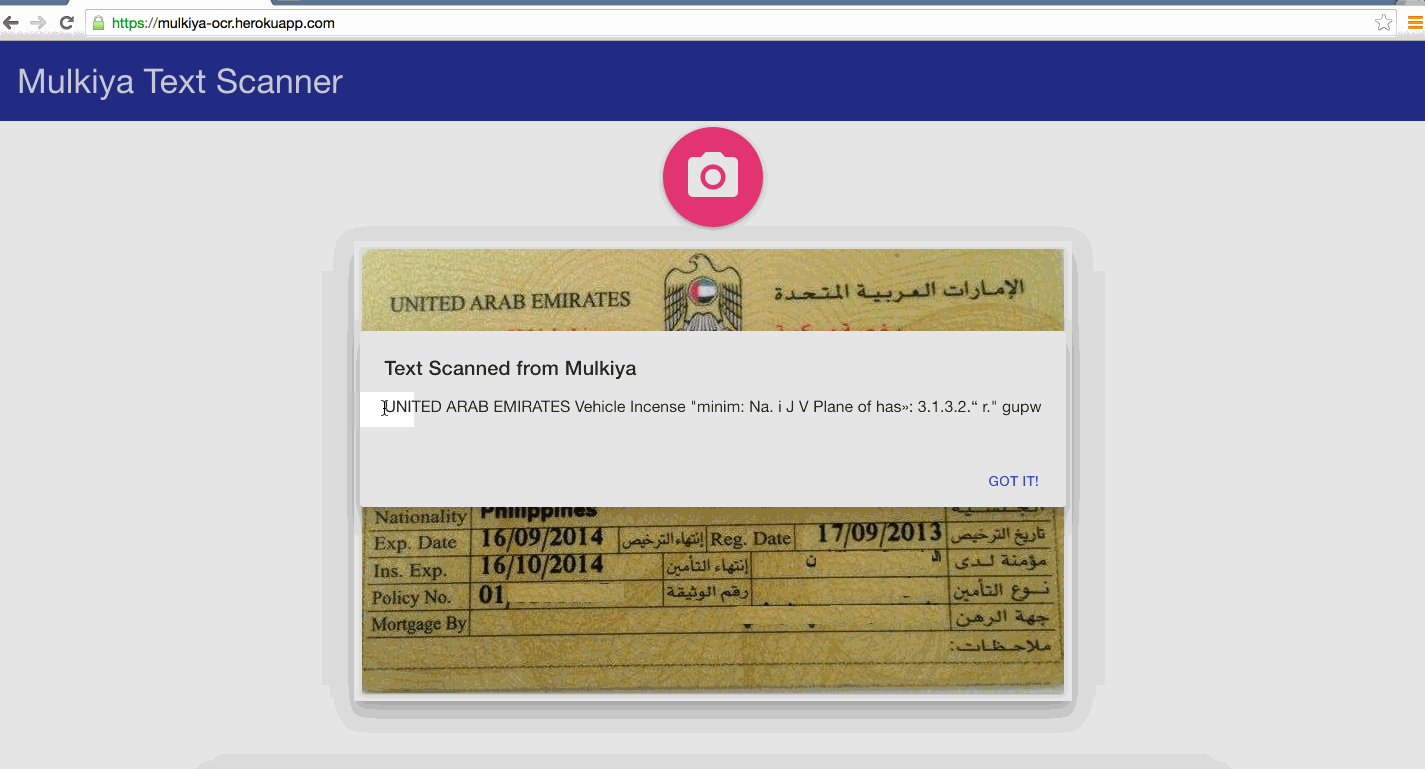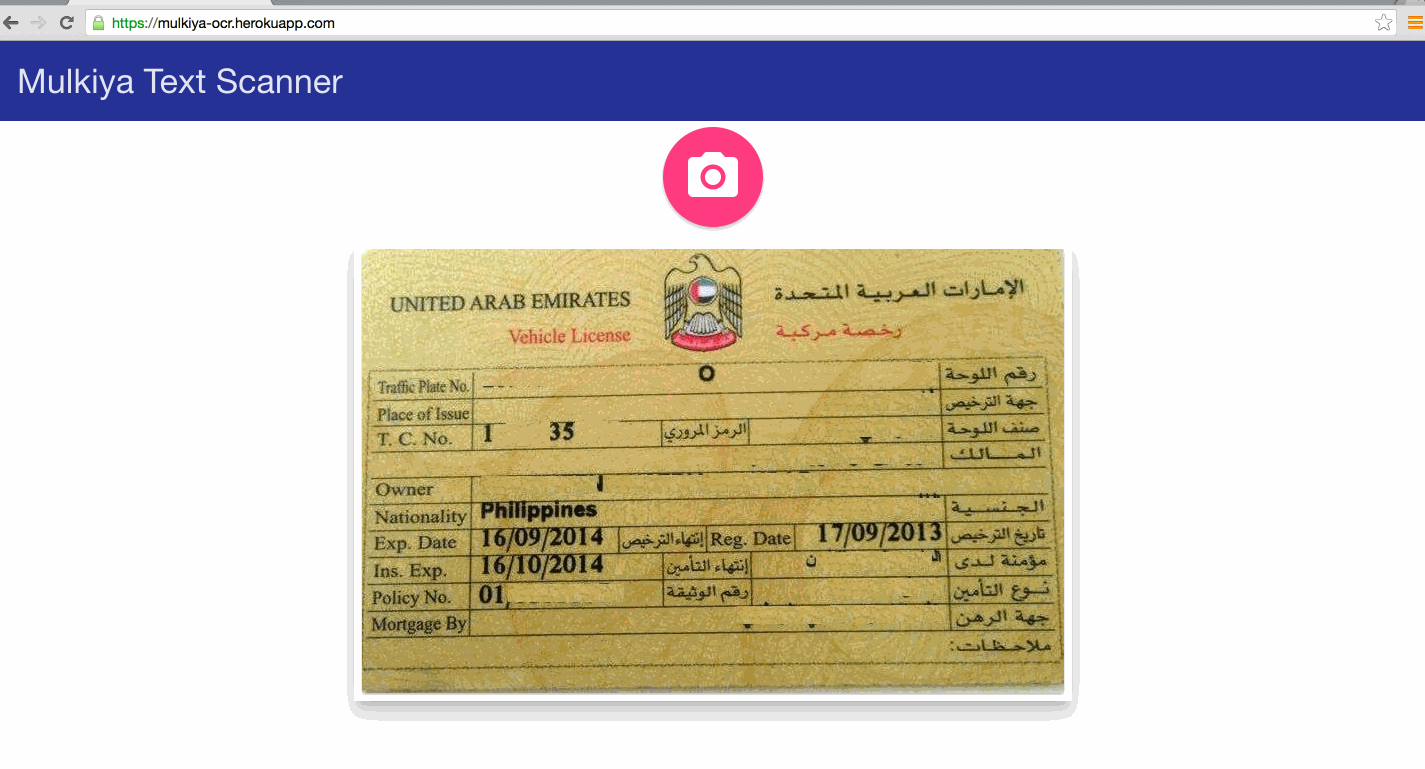
Structure
├── public (angularjs client side app)
│ ├── css
│ ├── images
│ └── scripts (angularjs services/controllers sciprts)
├── server (nodejs server side app)
│ └── app.js (Entry point to run the application)
| └── routes.js (routes file)
├── .buildpacks (heroku - installing nodejs/apt/tesseract multiple buildpacks)
├── .gitignore (git ignore)
├── Aptfile (heroku - for installing tesseract-ocr using apt-get)
├── bower.json (client side dependencies)
├── package.json (server side dependencies)
└── Procfile (heroku - process file)Stack
The application is built upon nodejs and angularjs frameworks, find bellow more details about stack.
Server Side Dependencies (NPM)
multerMulter is a node.js middleware for handling multipart/form-data.expressjsWeb application framework.node-tesseractA simple wrapper for the Tesseract OCR package for node.js
Client Side Dependencies (Bower)
angularjsSuperheroic JavaScript MVW Framework.ui-routrFor robust routing provider.angular-materialFor amazing material design support.ng-file-uploadAmazing angularjs file uploading directive additionally allows mobile devices to capture using camera.
Deployment
Mulkiya-ocr is deployed on heroku @ https://mulkiya-ocr.herokuapp.com/. There’s a great step by step tutorial provided by heroku for deploying a Node.js app in minutes have a look in case you’re interested in using heroku.
Deployment was the main challenge for this application since I had to install tesseract-ocr on server before deployment but thanks for heroku’s multiple buildpack support It was great experiment using heroku multiple buildpacks on this app.
Some useful links
- Using Multiple Buildpacks for an App
- heroku-buildpack-tesseract
- Implementing OCR for Heroku Rails app
- Use multiple buildpacks on your app
What’s next?
- Manipulate image before processing for example increase/reduce brightness/contrast so text can be extracted easily.
- Develop algorithm’s to extract right information from mulkiya such as model, car, year etc etc